
Hi, I'm Nathan Selikoff, a multidisciplinary senior engineer!
I'd love to join the Khan Academy Engineering team :)
Projects and previous work
Librarian and Scribe
Context
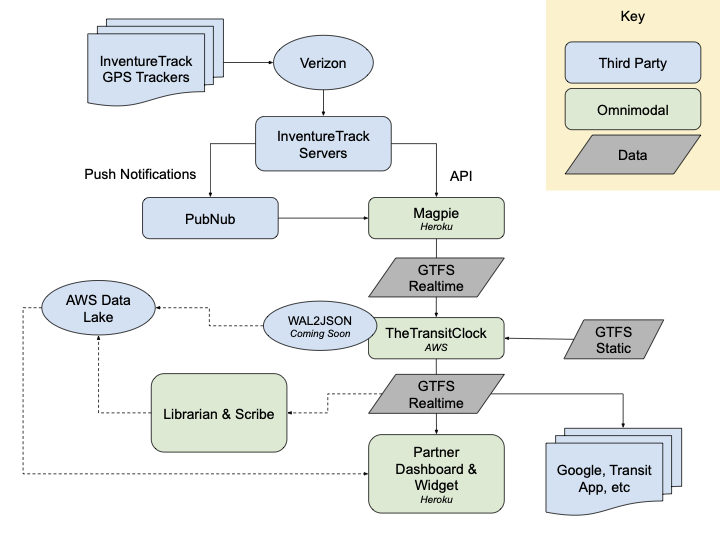
In the past three years, as CTO and co-founder of a startup, I’ve been designing and building a geospatial data platform from the ground up. Part of the challenge has been to engineer reliable and scalable cloud-based data pipelines that can fetch and archive mobility data from public transit, shared mobility (bicycles and scooters), and parking APIs - and transform, cache, and make the data available to the web application frontend.
Some of these third-party APIs are based on open data standards (yay!) and some of them are not. Some endpoints are reliable; many are not. We know some of the ways that we want to use the data now, but there will be future uses that we haven’t foreseen. To address these challenges, I designed and built a node.js microservice called scribe, and a Ruby on Rails + Sidekiq + Redis module called librarian.
Originally its own app, the Librarian registers real-time and static data feeds in a database, with metadata that describes where to fetch them from, how often to fetch them, and the last time they were fetched and archived. When the Librarian is run, a clock process will ping all registered feeds according to their configuration attributes, and when the time is right, will ask the Scribe to fetch and archive the feed in raw form into AWS S3, by POSTing with the appropriate info. If successful, the Scribe will respond with 201 Created and various metadata.
This system is in production with 14 data feeds for the City of Orlando, but is designed to be able to scale up to hundreds of cities and thousands of data feeds.
Links
The code is not open source, but I’ve extracted the READMEs for a little more context and would be happy to walk you through the system in further detail.
Filaments

Context
In 2014, I spent 6 days with about 200 students at Stone Middle School in Melbourne, Florida, teaching them the basics of making art with code. On the first day, I introduced the concept of “computational creation,” or “creative coding,” to the students, along with a discussion about using a sketchbook / design notebook in the creative process. After a few days learning Scratch, we switched to Processing, specifically Khan Academy’s implementation of Processing JS.
With Processing, we focused on more abstract, algorithmic art and code based on drawing simple shapes. We discussed drawing within a coordinate system, how color works on a computer versus with paint (additive vs subtractive), the draw loop, variables, and basic interactivity. I shared the “chaos game”, a stochastic method for generating a Sierpinski triangle, and talked about algorithmic drawing, giving them an example of mine called Filaments that many of them remixed.
Links
- Filaments on Khan Academy (make sure to check out the remixes!)
- My original Filaments blog post
- Full writeup of my teaching artist residency
Responses
Tell us briefly how your experiences and perspectives - whether personal, professional, academic, or otherwise - could contribute to the diversity of our team:
I come from an interdisciplinary art + tech background and have had quite a nontraditional career. My mom is an artist and my dad is a software engineer so I’ve grown up around both influences, which has benefited me greatly.
I’ve never worked in a traditional tech company, having spent most of my career freelancing with a variety of small businesses, non-profits, and later advertising and design firms. When I started my current startup with my business partner (where I’m moving away from the day-to-day), we talked a lot about fostering an inclusive, equitable and accessible environment where we and future team members could be ourselves, be honest with our needs, and look after our other passions and desires outside work. People describe me as kind, gentle, patient, and a good listener.
I’ve given a number of talks over the years, including a TEDx talk in Orlando, Florida (where I live) about the importance of having permission to fail. And not in a “move fast and break things” kind of way. I also have done some teaching over the years, including teaching middle school kids Scratch and Processing, and starting a local meetup group around Processing (a “creative coding” library). We actually used Khan Academy’s browser-based implementation of Processing at the time for the middle school class!
There’s a lot more I’d love to share, but I’ll leave you with one final tidbit: my wife and I rode bicycles 1000 miles across the US in the summer of 2009.
Briefly describe your experience building backend web services that deal with large volumes of requests per second:
I’ve been fascinated by scalability for awhile; I remember reading the “High Scalability” blog way before I was anywhere close to a project that needed to handle significant traffic.
As mentioned above, in the past three years, as CTO and co-founder of a startup, I’ve been designing and building a geospatial data platform from the ground up. Part of the challenge has been to engineer reliable and scalable cloud-based data pipelines without going overboard on complexity too early in the evolution of the product (i.e. before we actually have enough users to run into scalability problems).
Over that time I’ve experimented with pub/sub services (PubNub), streaming event pipelines (AWS Kinesis, Lambda), microservices (node.js), caching layers (Redis, AWS CloudFront), and more traditional web app backends (Ruby on Rails, PostgreSQL).
I’ve had to simplify some of my early architectural decisions in order to keep the entire system within a scope that I could handle myself - in some ways, going the opposite direction from your team by consolidating microservices to improve my speed of iteration and decrease complexity.
I’d be excited to work on a more mature platform and team like Khan Academy, which can justify the need for and support a large effort like Goliath.